
Google’s recent Penguin algorithm update has many online marketers frustrated. How does the update affect website traffic? What does it mean for a ... More
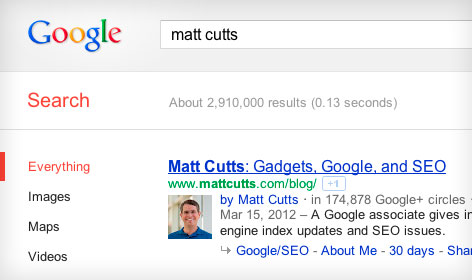
How Google Authorship Can Help Your Business
Authorship was started by Google to eliminate spam and duplicate content. It helps search users receive quality content relevant to their search that ... More

The Impact of Google Plus on Search Rankings
Last year, we spent a little time discussing the emerging Google social media channel. Like any new social media channel, it didn’t catch on with ... More
8 Tips for Optimizing Your YouTube Videos for Optimal Rankings and Viewership – Part II
Last week, we discussed how YouTube videos have become an integral part of web, and that businesses who don’t promote video content through YouTube ... More
8 Tips for Optimizing Your YouTube Videos for Optimal Rankings and Viewership – Part I
This is Part I of our series exploring the impact of YouTube and how you can leverage it to its full potential. Check back for Part II in a few days ... More

Google Will Now Include Panda in its Real-Time Algorithm
Up until now, Google’s “Panda” was just a periodic update by the search giant to ferret out sites engaging in spam and other nefarious activities. ... More

Getting to Know Your SEO: An Interview with SEOA’s Stone Reuning
Stone Reuning has been doing SEO since the pre-Google era, back when Yahoo was the king of search. That alone would be impressive, but it’s really ... More
Link Building Post Panda – Is Article Marketing Still Viable?
The short answer is yes, if you’re mindful of the needs of your audience and make quality over quantity the core of your link building efforts… In ... More
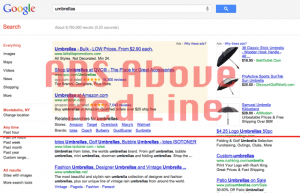
Keeping your Content Above the Fold and Easy to Find
All the way back at the beginning of 2012, Google rolled out a new page layout algorithm. This October, the search giant provided an update on the ... More