

If you’re reading this blog post, then chances are you are having a problem with your site not showing up on Google or another search engine - or ... More

Reasons Why Your Site May Be Invisible to Google: Cause #1
Our main goal here at SEO Advantage is for all our clients to consistently appear at the top of Page 1 in Google and all other search engines. When ... More

SSL Connections and How They Keep Online Data Safe
Ensuring that your business’s online data remains secure is of utmost importance. Ever since the infamous Target data breach in 2013 in which over 40 ... More

5 Lessons to Take Away from Eye-Tracking Studies
For marketers concerned that their web content is not performing to its maximum potential, eye-tracking software and heat maps can tell you where your ... More
SEO Roundup: August 28, 2013
Listen to the online marketing sphere for five minutes and chances are you'll hear someone cry the death knell of SEO, which is why we absolutely love ... More
SEO Roundup: August 14, 2013
We've seen tons of great guides and articles around the SEOsphere this past week, but one of our favorites has to be this fantastic visual guide from ... More
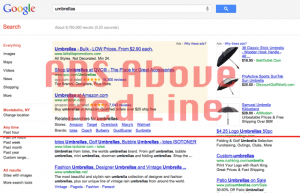
Keeping your Content Above the Fold and Easy to Find
All the way back at the beginning of 2012, Google rolled out a new page layout algorithm. This October, the search giant provided an update on the ... More
URL Syntax and How It Can Dramatically Affect SEO
While it may seem like a minor detail, we can’t tell you how many times we’ve spotted bad URLs in a website…in fact, it’s one of the first things that ... More
Joomla 3 vs. WordPress 3.5: A True Mobile CMS
Content Management Systems like Wordpress and Joomla are giant beacons of success in the software world, proving that free (as in beer), open source ... More